Use cases and examples of utilizing graph technology for public sector data management and data analysis.
Graph Databases are the (not-so-) new must-have in your tech stack. Over the past few decades, more and more tech giants (Facebook, Twitter, and Google leading the way) have started migrating data into graph databases to not only store and retrieve data in a highly scalable way, but also incorporate models on graph structures to produce highly effective recommendations.
What makes graph databases so enticing to these companies with gargantuan data? And can the public sector benefit from this technology in similar ways?
What differentiates Knowledge Graphs from RDBMS?
RDBMS Basics
Relational Database Management Systems (RDBMS’s) refers to databases that store their data in a structured format with rows and columns, and have a schema that demonstrates the linkage between different tables within a database. RDBMS’s are generally queried with SQL (Structured Query Language) or a similar equivalent, and are great for fairly static (non-changing) and normalized data structures.
To give a basic use case of RDBMS, let’s pretend we are starting a company called GovBook, the government equivalent of Facebook, that allows users to register for an account, submit government documents, and interact with government officials in a social setting. There are thousands of data attributes being captured for each person, which each must get placed into a specific table in a database. We could structure our database schema to have a User Registration table, containing all information for a user that is given during registration, and a Documents table, containing a link to a pdf for every Document that a user has uploaded to the system. There would be some kind of unique identifier, called a primary key, to differentiate users in the User Registration table, and this key would also serve as the foreign key to link the two tables to each other.
This seems like a very nice and logical way to deal with data management, but of course there are pros and cons to this type of structured system. In this example, the biggest pit-fall is that all entered data be able to fit into the pre-designated columns of a table. But what if, a year into business, GovBook decides they want to capture additional data during registration. At the start, they capture Name, Username, Password, Email, and Gender, but they now want to add a field for Date of Birth.
NoSQL Graph Databases
This problem gave rise to the concept of NoSQL (Not Only SQL) databases, which allows for data storage that is:
- non structured
- highly scalable
- schema less
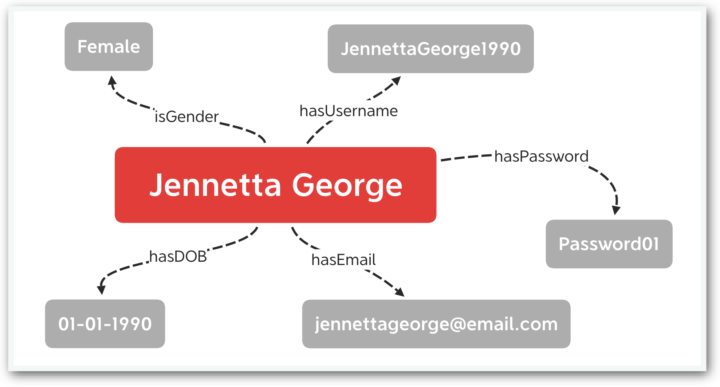
Over the past decade, there has grown a huge popularity in one particular type of NoSQL database, the Graph Database. Instead of interpreting data as rows and columns, graph databases use subject-predicate-object triples. So in the example above, instead of inserting a row of data Jennetta George , JennettaGeorge1990, Password01, jennettageorge1990@email.com, Female into a Registration table, the following triples would be added to a graph:
- Jennetta George -> hasUserName → JennettaGEorge1990
- Jennetta George -> hasPassword -> Password01
- Jennetta George -> hasEmail -> jennettageorge1990@email.com
- Jennetta George -> hasGender -> Female
The subject and object of a triple are the nodes of the graph and the predicates are the edges.
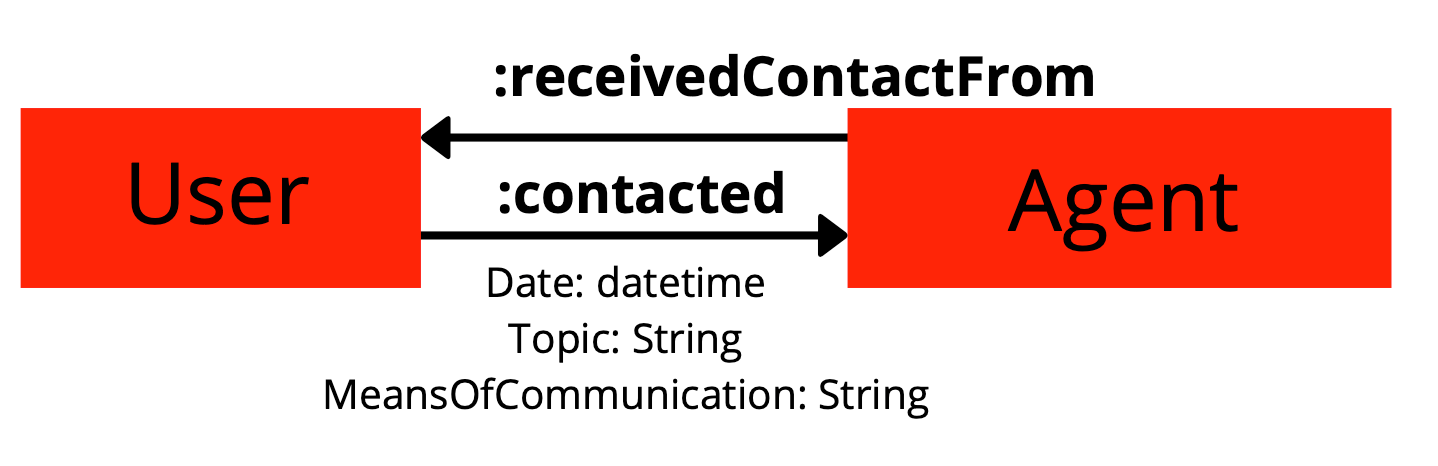
Do not let the term Relational in RDBMS fool you — in graph databases, the edges (or relationships between nodes) are treated as first class citizens, and this is where the true magic of graph databases comes from. Edges act as the connection between all data in the graph, and act as a rich source of data in themselves. Depending on your choice of graph database, you have the option to label, give direction, and add other informative attributes to your edges. For instance, if we consider the triple User — :contacted -> Agent , we can build many attributes and labels into the relationship contacted. We can subscribe an inverse relationship, receivedContactFrom, as well as assign labels like date, topic, and means of communication. If you stop and think about how to implement this in a relational database, you can see how much heavier of a lift creating this structure becomes.
Benefits of Using a Graph Database
Let’s dive into how this different way of approaching data management affects the data’s lifecycle.
Faster Querying Speed
Just like how relational databases rely on a SQL language to retrieve data, graph databases have their own specialized query language as well. Neo4J, one of the leading graph database tools, using a language called Cypher.
One benefit of using graph databases to query data can be readily seen in the following example. Consider an analyst who wants to find all users who have connected with a government agent who lives in the New York City area. In a relational database, this simple sounding query can get quite complex, both in time and query complexity. This query would include performing multiple select statements across multiple joins, depending on how many tables the data is stored in that is relevant to this search.
Source: https://towardsdatascience.com/graph-databases-for-the-public-sector-1a50d0563fff